Tájékoztató az összetett keresőfelület használatához
Az Új magyar etimológiai szótár tartalma erősen strukturált XML-adatbázisként készült el, így az egyszerű címszó szerinti keresésen túlmenően lehetőség van a benne foglalt információ különböző szempontok szerinti részletes vizsgálatára is. Az összetett keresés felülete bármikor megnyitható a weboldal tetején megjelenő egyszerű keresődoboz melletti ' Összetett keresés' gombra kattintva. A megnyíló ablak elrendezése az alábbi ábrán látható.
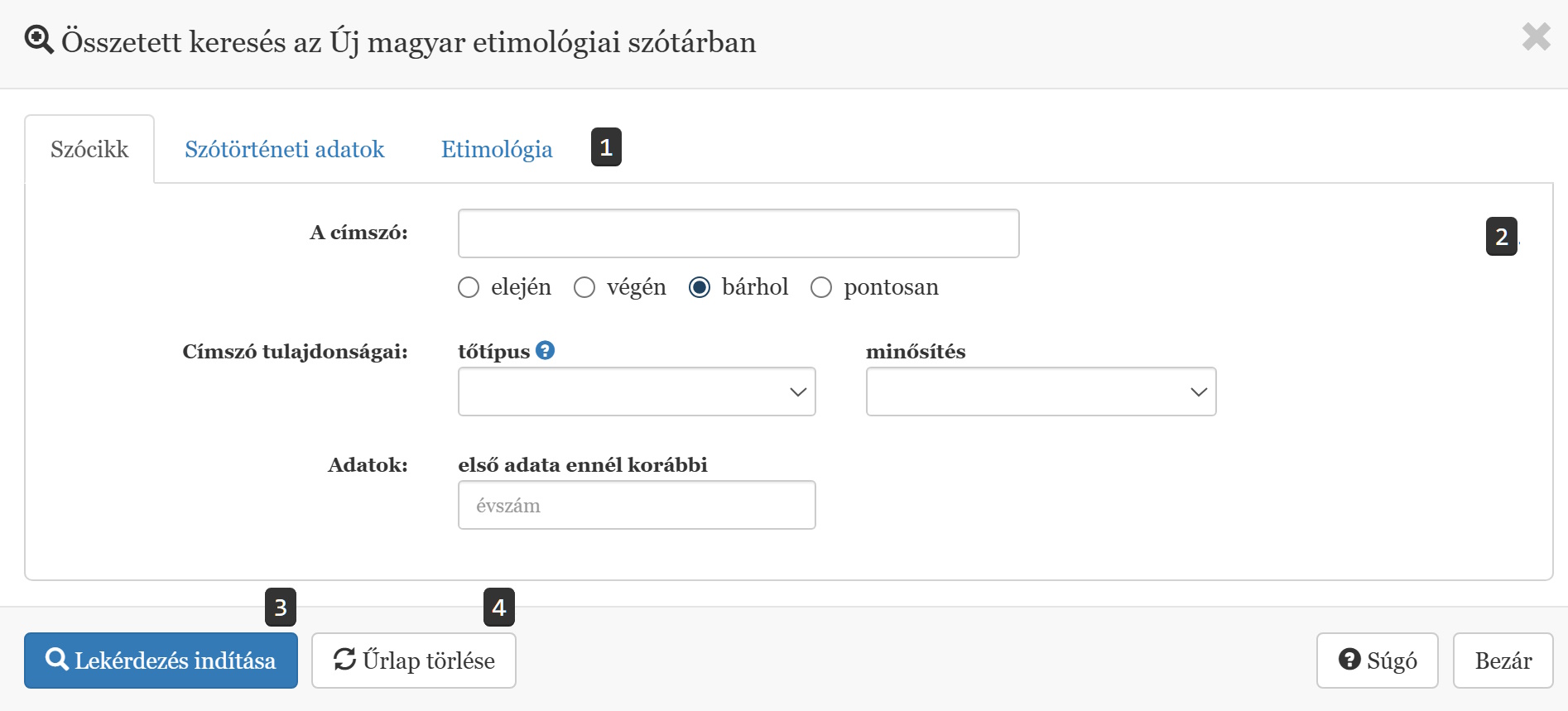
Az összetett keresés első lépéseként mindig azt kell eldöntenünk, hogy milyen típusú szótári elemeket vizsgáljunk 1. Lehetőség van teljes szócikkek, egyes szótörténeti adatok és az etimológiák különféle szempontok szerinti kigyűjtésére is. Az említett szótári egységek mindegyikéhez külön lap tartozik a keresőfelületen. A megfelelő lap kiválasztása után az adott elemhez tartozó szűrőfeltételek jelennek meg az ablakban 2. A kereséshez legalább egy feltétel megadása szükséges, de a szűrőfeltételek tetszőleges számban szabadon kombinálhatók is egymással. A lekérdezés elindításához kattintsunk a Lekérdezés elindítása gombra 3. A keresés után a korábban megadott szűrőfeltételek megőrződnek (amíg ugyanabban a böngészőablakban maradunk). Szükség esetén az űrlap összes mezőjét egyszerre törölhetjük az 'Űrlap törlése' gomb segítségével 4.
Az eredmények az alább látható módon, egy oldalon, közvetlenül egymás alatt jelennek meg.

A találati lista elemei tartalmazzák a címszót 5, és szükség esetén a találat helyének pontosabb meghatározását is 6, valamint adatok és etimológiák esetében a megtalált szótári egységet 9. Ha a keresett elem szócikk, akkor a listában csak a címszó látható, de többféle lehetőség van a teljes szócikk megjelenítésére is. Minden egyes találat mellett megjelenik egy ikon 7, amelyre kattintva a teljes szócikk megnyitható egy új böngészőablakban. Továbbá minden egyes találat kinyitható és becsukható a sor jobb szélén megjelenő lefelé, ill. felfelé mutató nyíl gombbal 8 vagy a találatot befoglaló szürke téglalap tetszőleges részén dupla kattintással. Kinyitás után a teljes szócikk láthatóvá válik közvetlenül a találati listában, a keresett elem pedig sárga kiemelést kap a szócikken belül. Technikai okokból a találati lista szakaszosan jelenik meg, az oldal aljára görgetve mindig automatikusan töltődnek be a további találatok.
A szűrőfeltételek részletes bemutatása
Az alábbiakban minden egyes szűrőfeltételt részletesen bemutatunk a keresett elem típusa szerint csoportosítva. Ezek ismertetése előtt következzen néhány olyan általános tudnivaló, amely a felületen található több különböző szöveges szűrőre általánosan érvényes.
A szöveges szűrőknél alkalmazott egyszerű lekérdezőnyelv
A felületen több olyan szűrőfeltétel található, amelynek segítségével egyes szótári egységek szövegének tartalmára tehetünk megkötést. Az ilyen mezők alatt található elején, végén, bárhol v. pontosan kapcsolók segítségével azt határozhatjuk meg, hogy a beírómezőben megadott karaktersort a rendszer a megfelelő szótári elem melyik részén keresse. (Az ezek után következő 'RegExp' jelentését lásd alább.) Az ilyen mezőkben megadott keresőkifejezéseket a rendszer speciálisan értelmezi, aminek köszönhetően összetettebb feltételeket is megfogalmazhatunk.
- Egy összefüggő karaktersor megadása esetén a rendszer olyan szövegegységeket talál meg, amelyek tartalmazzák a megadott karaktersort.
- Szóközökkel elválasztott több karaktersor megadása esetén a találatok tartalmazni fogják a megadott karaktersorok mindegyikét, de egymástól tetszőleges távolságban és sorrendben. Ez lényegében egy logikai ÉS kapcsolatnak felel meg.
- A virgula vagylagosságot fejez ki, tehát ha két (vagy több) karaktersort virgulával elválasztva adunk meg, akkor a találatok a karaktersorok valamelyikét fogják tartalmazni. pl:
kutya|macskajelentése: a szövegben forduljon elő a kutya VAGY a macska karaktersor. Tőváltozatokra kereshetünk pl. így:kutya|kutyá. - A fenti logikai kapcsolatokat egyszerűen kombinálhatjuk is:
kutya|macska ugat|nyávog= a szövegben szerepeljenek a kutya VAGY macska karaktersorok ÉS az ugat VAGY nyávog karaktersorok is. - Ha azt szeretnénk, hogy a rendszer a megadott kifejezést ne értelmezze speciálisan, tehát pl. egy többszavas kifejezést keresünk betű szerint a megadott alakban, akkor az egész keresőkifejezést tegyük idézőjelbe.
"a kutya ugat"= a szövegben szerepeljen az a kutya ugat teljes karaktersor pontosan ebben a formában. - A szöveges szűrők mindig érzéketlenek a kis- és nagybetűkre.
Keresés reguláris kifejezésekkel
A szöveges szűrők alatt található kapcsolók segítségével kiválaszthatjuk a RegExp opciót is. Ebben az esetben nem a fent ismertetett egyszerű lekérdezőnyelvvel, hanem valódi reguláris kifejezésekkel adhatjuk meg a keresett karaktersort. Az alábbiakban röviden ismertetjük a reguláris kifejezésekkel kapcsolatos legfontosabb tudnivalókat. Mivel általánosan használt technológiáról van szó, a további részletek számtalan forrásból megismerhetők akár online forrásokból is.
- A reguláris kifejezésekkel történő keresést is úgy valósítottuk meg, hogy az érzéketlen a kis- és nagybetűk különbségére.
- Minden betű önmagának felel meg, de bizonyos speciális karaktereknek különleges jelentése van. Ezek a
.,+,*,?,{,},\,[,],(,),|,^,$ - A
.tetszőleges karaktert helyettesíthet. - Szögletes zárójelek
[]között egy karakterosztályt definiálhatunk. Az adott pozícióban csak a zárójelek között megadott karakterek fordulhatnak elő. Kötőjellel egy folyamatos karaktertartományt is megadhatunk. Pl. a[a-zöüóőúéáí]jelentése a-z-ig minden betű, továbbá az összes ékezetes magyar magánhangzó, tehát lényegében az összes magyar betű. Definiálhatunk negatív osztályt is, ilyenkor a nyitó zárójel után '^' áll. Pl.[^ab]jelentése: tetszőleges karakter, kivéve az 'a'-t és a 'b'-t. - Kvantorok:
+,*v.?egy karakter, karakterosztály vagy kerek zárójelbe foglalt szekvencia után írva azt jelenti, hogy a megadott karakterek hányszor fordulhatnak elő az adott helyen. '+': egy vagy több előfordulás; '*': nulla vagy több előfordulás; '?': nulla vagy egy előfordulás. Az előfordulások számát szabályozhatjuk ennél pontosabban is kapcsos zárójeles kifejezések segítségével. Pl..{2,6}jelentése: legalább 2, de legfeljebb 6 tetszőleges karakter. A két szám közül akár az első, akár a második elhagyható (a vesszőt ki kell tenni), ebben az esetben legalább, ill. legfeljebb a megadott számú karakterről van szó a másik korlát megadása nélkül. - A reguláris kifejezéssel megadott szekvencia bárhol illeszkedhet a vizsgált adatban. Ha a megadott mintázatot az adat elején vagy végén keressük, akkor használjuk a
^(illeszkedés az adat elején) és/vagy a$(illeszkedés az adat végén) szimbólumokat. Pl.^f[eö]l.+: 'fel' vagy 'föl' karaktersorral kezdődő adat, mely további karaktereket tartalmaz;.+ás$: '-ás'-ra végződő adat. Ha mindkét szimbólumot használjuk, akkor kizárólag a megadott mintázattal pontosan egyező adatokat kapjuk meg. - Ha bármelyik speciális karaktert szó szerint szeretnénk keresni (tehát az adott karaktert kivételesen nem speciális funkciójában szeretnénk használni), akkor tegyünk elé
\karaktert. Pl. a.jelentése 'tetszőleges karakter', de\.jelentése kizárólag a '.' karakter. - Vagylagosságot a
|segítségével fejezhetünk ki. A kerek zárójelek között virgulával elválasztott karakterszekvenciák közül bármelyik állhat az adott helyen. Pl.fel(ugrik|áll)jelentése: 'felugrik' vagy 'feláll'.
Reguláris kifejezések lehetnek szintaktikailag hibásak is, ha például a zárójelezést elrontjuk, vagy a kvantorokat nem megfelelően használjuk. Ilyen esetben a keresés sikertelen lesz, és a rendszertől figyelmeztetést kapunk, de nem történik semmi baj. Nyissuk meg újra a keresőpanelt és javítsuk a hibás reguláris kifejezést, majd indítsuk újra a lekérdezést!
Szócikkek
A szócikkekre vonatkoztatható szűrők három csoportra oszthatók, ezek egymás alatt külön blokkokban jelennek meg a felületen.
▪ A címszó
A szócikkekben található címszavakra (szócsaládok esetén több címszó is lehet), valamint az ezekhez köthető származékokra és megszilárdult ragos formákra kereshetünk a fent ismertetett lekérdezőnyelv használatával.
▪ A címszó tulajdonságai
Adott tőtípusba tartozó, illetve adott minősítéssel († - kihalt szó; ∆ - archaikus szó; × - nyelvjárási szó) ellátott címszavakat kereshetünk. A tőtípusok felsorolása, ill. a kódok magyarázata megtalálható itt: Tőtípusok.
▪ Adatok ideje
Egy évszám megadásával kereshetünk olyan szavakat, amelyeknek első adata a jelzett időpont előtt vagy után keletkezett.
Szótörténeti adatok
Ezen az oldalon a szócikkek szótörténeti részében felsorolt adatokra és az azokhoz kapcsolódó kiegészítő információkra lehet keresni.
▪ Az adat
A szöveges szűrőkre általánosan érvényes módon adhatjuk meg, milyen szöveges tartalmat keresünk. Ezen túlmenően kétféle keresési mód közül választhatunk. Ha az egyszerűsített latin átírás szerint szeretnénk keresni, akkor minden ékezetet/mellékjelet hagyjunk el, továbbá minden különleges régi vagy más írásrendszerbe tartozó grafémát is az annak megfelelő modern latin betűvel helyettesítsünk. Alább felsoroljuk azokat a különleges karaktereket, amelyek átírása nem egyértelmű:
| ß* | → | sz |
| ɓ** | → | zs |
| ʟ*** | → | cs |
| ꝛ | → | r |
| ꝯ**** | → | 9 (számjegy) |
* hosszú s és ʒ kombinációja és hasonló ligatúrák vagy digráfok jelölésére használt karakter; ** az eredetiben hosszú s-ből és mellette egy ívelt vonásból álló karakter jellemzően zs hangértékben; *** 'huszita cs'; **** 'con' vagy szóvégi 'us' értékben
Ha a betűhű eredeti írásmódot választjuk, a beírómező alatt virtuális billentyűzet jelenik meg, melynek segítségével a szótárban előforduló összes speciális karaktert be tudjuk vinni. Ebben az esetben a rendszer kizárólag a keresőkifejezésnek tökéletesen megfelelő adatokat fogja megtalálni. A virtuális billentyűzeten bármelyik alapbetűre kattintva megjelenik annak összes speciális, ill. ékezetes változata, miközben az alapbetű megjelenik a beírómezőben is. Ha bármelyik speciális változatra kattintunk, a beírómezőben az alapbetű erre a karakterre változik. Ha az egérmutatót hosszabban valamelyik karakter fölött tartjuk, megjelenik annak pontos Unicode szerinti megnevezése.
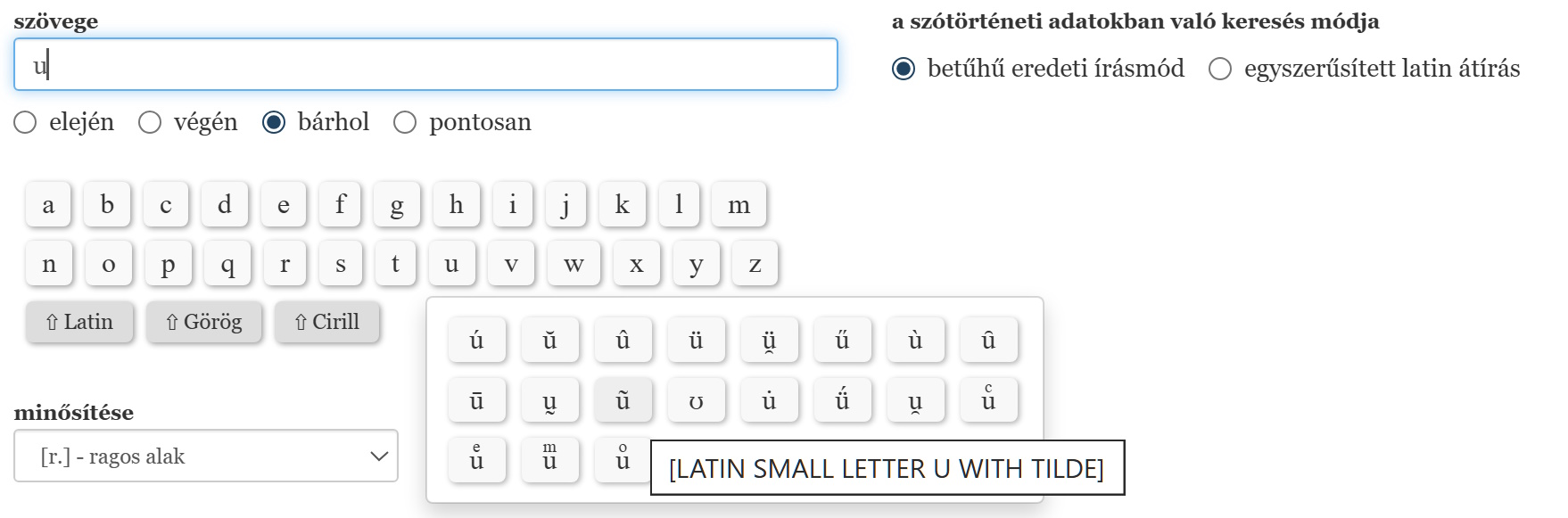
Megszorítást adhatunk meg az adat minősítésére is ([▽] - legkorábbi ikes alak; [🖉] - átírt alak; [sz.] - származék; [r.] - ragos alak; [hn.] - helynév; [szn.] - személynév; [állatn.] - állatnév), több minősítés megadása esetén mindegyik feltételnek egyszerre teljesülnie kell.
▪ Az adat forrása
Szótárunkban az adatok forrását rövidítésekkel jelöljük. A rövidítések feloldása megtalálható a forrás- és irodalomjegyzékben. A forráskód mezőben ezeket a rövidítéseket kell megadni, de ehhez segítséget nyújt a legördülő menü, amelyben minden olyan bibliográfiai tétel megjelenik, amelynek bármelyik része megfelel a mezőbe pillanatnyilag begépelt karaktersornak. Pl. a tihanyi apátság alapítólevelére TA. rövidítéssel hivatkozunk, de akár az 'alapítólevél' karaktersor begépelése után is felajánlja a felület a 'TA.' rövidítést. A megfelelő forráskódot kattintással választhatjuk ki. Az egérmutatót a listában található rövidítések fölött hagyva rövid idő után megjelenik azok kifejtése, vagyis a teljes bibliográfiai adatsor.
▪ Keletkezési idő
Az adatok keletkezési idejére többféle módon is szűrhetünk. A keresés módja alatt válasszuk ki, hogy évszámra, évszázadra, vagy tetszőleges időintervallumra szeretnénk-e keresni. A felület ennek megfelelően meg fog változni, és a kívánt értékeket értelemszerűen tudjuk megadni. Mivel a szótár a keletkezési időt nem minden esetben pontos évszámmal adja meg, az erre való szűrés algoritmusa nem magától értetődő. A szótárban szereplő e. (előtt), u. (után), k. (körül) rövidítések, a valamely század elejére, közepére vagy végére való hivatkozás, ill. a kötőjellel megadott intervallumok figyelembe vételével minden adat keletkezését mögöttesen egy célszerű módon meghatározott időintervallummal reprezentáljuk. Találatot akkor adunk, ha az adat időintervalluma, és a szűrőfeltételben megadott időpont vagy időintervallum között van átfedés. Az évszámra történő szűrés esetén a csak pontos egyezés opció kiválasztásával jelezhetjük, hogy kizárólag olyan adatokat keresünk, amelyek mindenféle bizonytalanság nélkül pontosan az adott évben keletkeztek, így pl. nem kapjuk meg azokat a találatokat, amelyek a szótár szerint az adott évszázadban keletkeztek, ahogy azokat sem, amelyek ugyan a megadott évszámot tartalmazzák, de e., k. vagy u. módosítóval.
Etimológia
Bár az etimológiai magyarázatok alig strukturált folyó szövegként jelennek meg az Új magyar etimológiai szótárban, a szavak eredetével kapcsolatos fontosabb információkat mögöttesen úgy ábrázoltuk, hogy lehetőség van az ezekkel kapcsolatos keresésekre is.
▪ Eredet
Legördülő menükből választhatjuk ki az eredettípusra vontakozó szűrőfeltételeket, az ezeken belül előforduló altípusokat, valamint jövevényszavak esetében az átadó nyelvet és annak nyelvváltozatát. A listák tartalma dinamikusan változik a korábbi legürdülő listákban kiválasztott értékek függvényében. Ezekkel a szűrőfeltételekkel alapvetően az etimológiai magyarázatok bevezető mondatának tartalmára tudunk keresni formalizált módon.
A nyelvújítási képződmény (⌘) opció kiválasztásával kereshetünk nyelvújítási szavakat.
▪ Átvételek a magyarból
Az átvevő nyelv kiválasztásával kereshetünk olyan szavakat, amelyek a magyarból kerültek át más nyelvekbe.
▪ Adatok
Az etimológiai magyarázatokban gyakran szerepelnek főleg más nyelvekből származó adatok, amelyek valamilyen módon kapcsolódnak a címszóhoz. Kereshetünk ilyen adatokat a szótörténeti adatoknál már megismert módon, de lehetőség van az adatok nyelvére és nyelvváltozatára történő keresésre is. Az etimológiákban előforduló adatok általában idegen nyelvűek, így itt az egyszerűsített latin átírás kicsit eltér a magyar szótörténeti adatoknál alkalmazottól, valamint a betűhű kereséshez használt virtuális billentyűzet is bővebb. A magyar szótörténeti adatokhoz hasonlóan minden ékezetet elhagyunk, valamint a görög és cirill betűknek a hangértékük szerint jellemző latin megfelelőjét használjuk. A nem nyilvánvaló megfeleltetéseket alább közöljük:
| ß | → | ss |
| æ | → | ae |
| ð | → | th |
| þ | → | th |
| œ | → | oe |
| ƕ | → | hv |
| ƥ | → | p |
| ʌ | → | l |
| ʔ | → | ' |
| ȣ* | → | V1 |
| ȣ̈** | → | V2 |
| ɜ*** | → | V3 |
| ɯ | → | i |
| görög | ||
| θ | → | th |
| ξ | → | ks |
| χ | → | kh |
| ψ | → | ps |
| cirill | ||
| й | → | j |
| х | → | h |
| ж | → | zh |
| ц | → | ts |
| ч | → | ch |
| ш | → | sh |
| щ | → | sch |
| ъ | → | " |
| ь | → | ' |
| ы | → | y |
| ю | → | ju |
| я | → | ja |
| ё | → | jo |
| я | → | ja |
* bármilyen rövid veláris magánhangzó alapnyelvi rekonstruált szóalakokban; ** bármilyen rövid palatális magánhangzó alapnyelvi rekonstruált szóalakokban; *** bármilyen alsó nyelvállású rövid magánhangzó alapnyelvi rekonstruált szóalakokban
▪ Szöveg
Végezetül használhatjuk a szabad szavas keresőt is, ha az etimológia teljes szövegében szeretnénk megtalálni valamilyen információt, amit más módon nem sikerült. A kereső az itt megadott kulcsszavakat az etimológiai blokkok teljes szövegében keresi, és a megtalált kulcsszavakat a találatokban külön sárga kiemeléssel jelzi. FIGYELEM! A szabad szavas kereső nem a fent ismertetett egyszerű lekérdezőnyelvet használja. Ide csak írjuk be a keresett kulcsszavakat, és a rendszer automatikusan megtalálja azok bármilyen ragozott formáját az eredeti szövegben.